Advanced Analytics
Clustering
Clustering groups similar data into clusters. Below is a guide on configuring clustering in the Empowered AI module.
Step 1: Configuring the Clustering Rule
Number of clusters
In the Clusters section, specify the number of clusters to be created. This number depends on the nature of your data and the objectives of your analysis.

Complete the configuration of other settings, such as Start Date, Build Time Frame, Scheduler options, and Field to Analyse. These settings are the same as those described in the common configuration guide.
Step 2: Running the Rule
After configuring all settings, click Save to save the rule, then click Run to start the clustering process or Save & Run to start the process immediately.
Performance Tab for Clustering
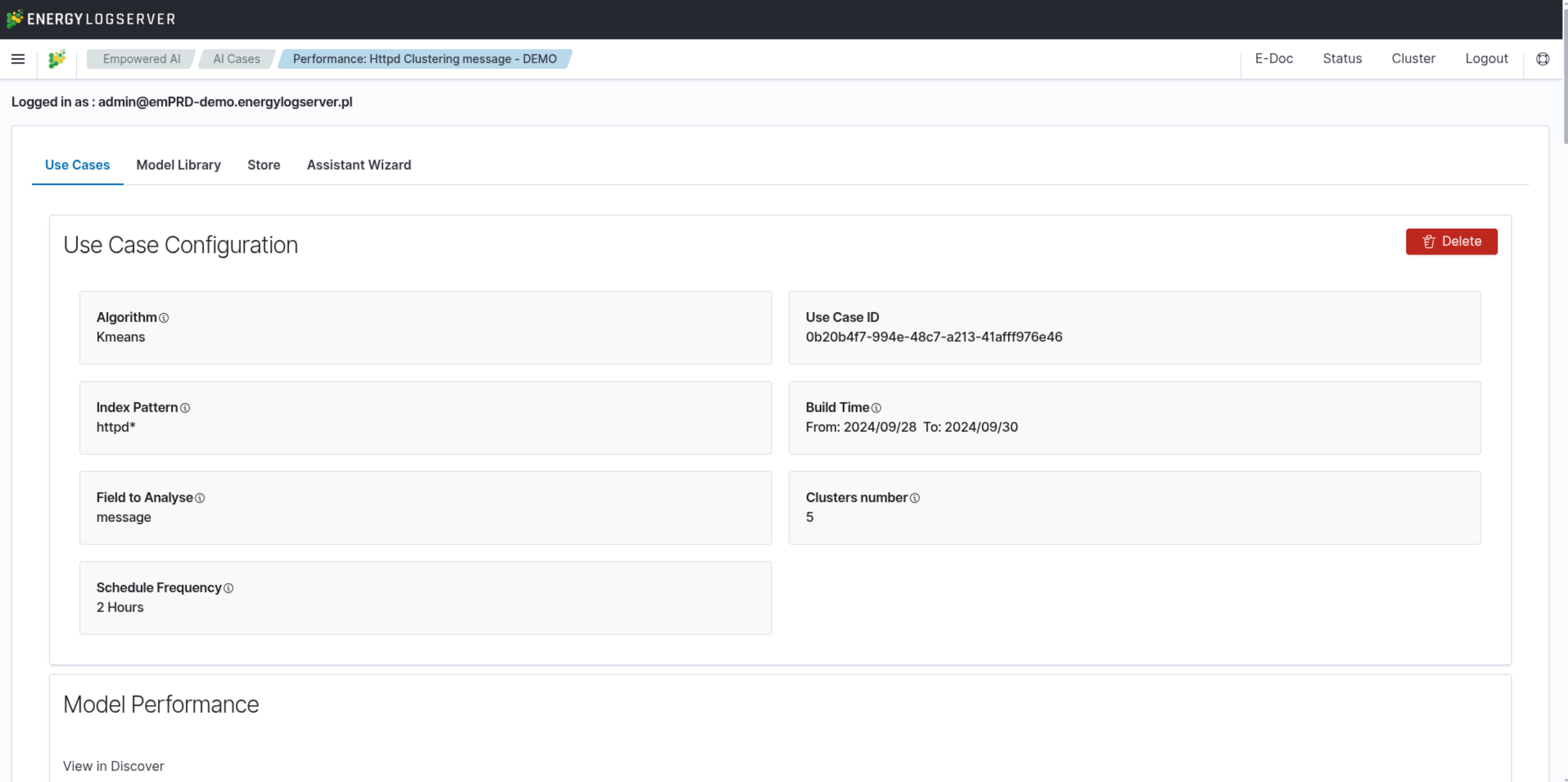 The Performance Tab provides comprehensive visualizations and detailed information on clustering results.
The Performance Tab provides comprehensive visualizations and detailed information on clustering results.
Elbow Method and Optimal Number of Clusters
The elbow method is a commonly used technique in clustering analysis to determine the optimal number of clusters. It involves plotting cluster quality against the number of clusters and identifying the point where the quality improvement slows down, forming an “elbow” shape on the graph. This point indicates the optimal number of clusters.
Cluster Quality Chart
The Cluster Quality Chart visualizes the relationship between the number of clusters and the cluster quality. The x-axis represents the number of clusters, and the y-axis represents the cluster quality score. The goal is to identify the point where adding more clusters does not significantly improve quality, which is the optimal number of clusters.
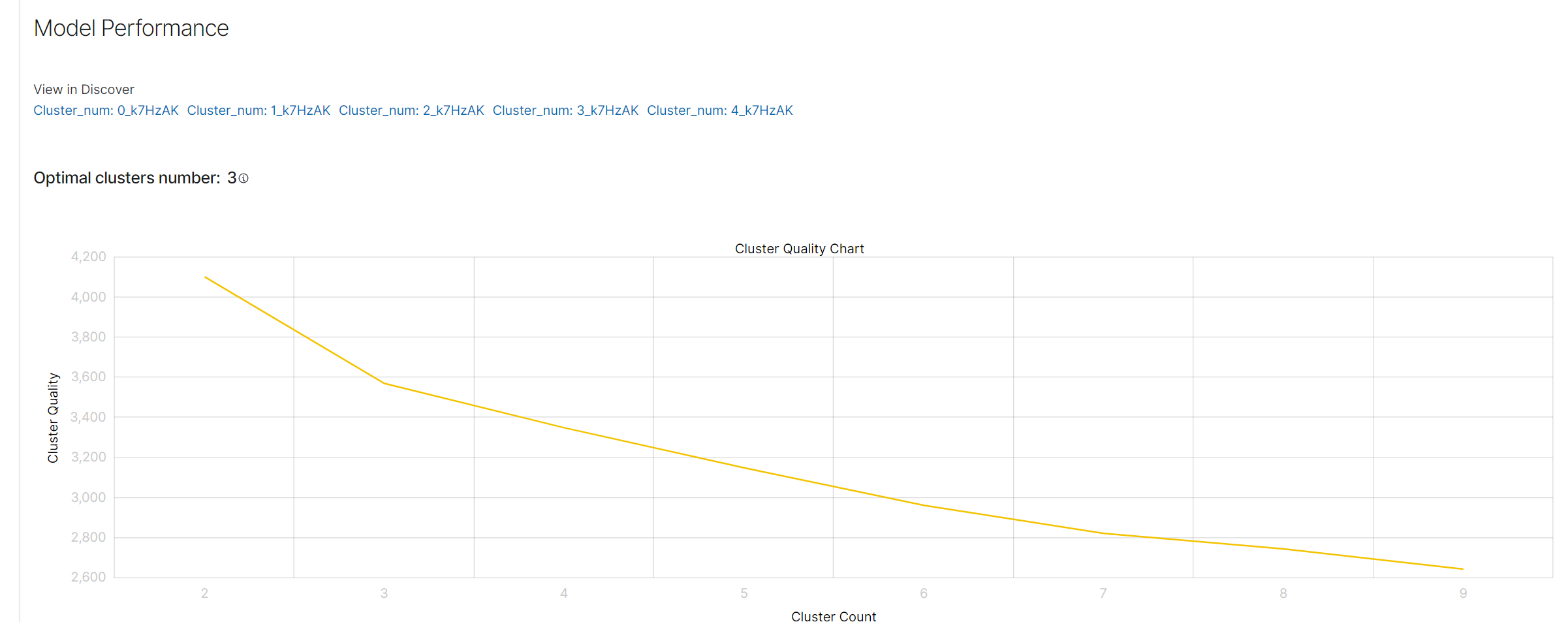
In this example, the optimal number of clusters is 3, as indicated on the chart.
Cluster Distribution Chart
Below the elbow method chart in the Performance tab, there is a cluster distribution chart. This chart shows the distribution of documents among clusters along with their centers. Each dot on the chart represents a document assigned to a specific cluster.
Clicking on a Dot: Clicking on any dot on the chart will display a preview of the document it represents. The preview contains detailed information about the document, such as the message content.
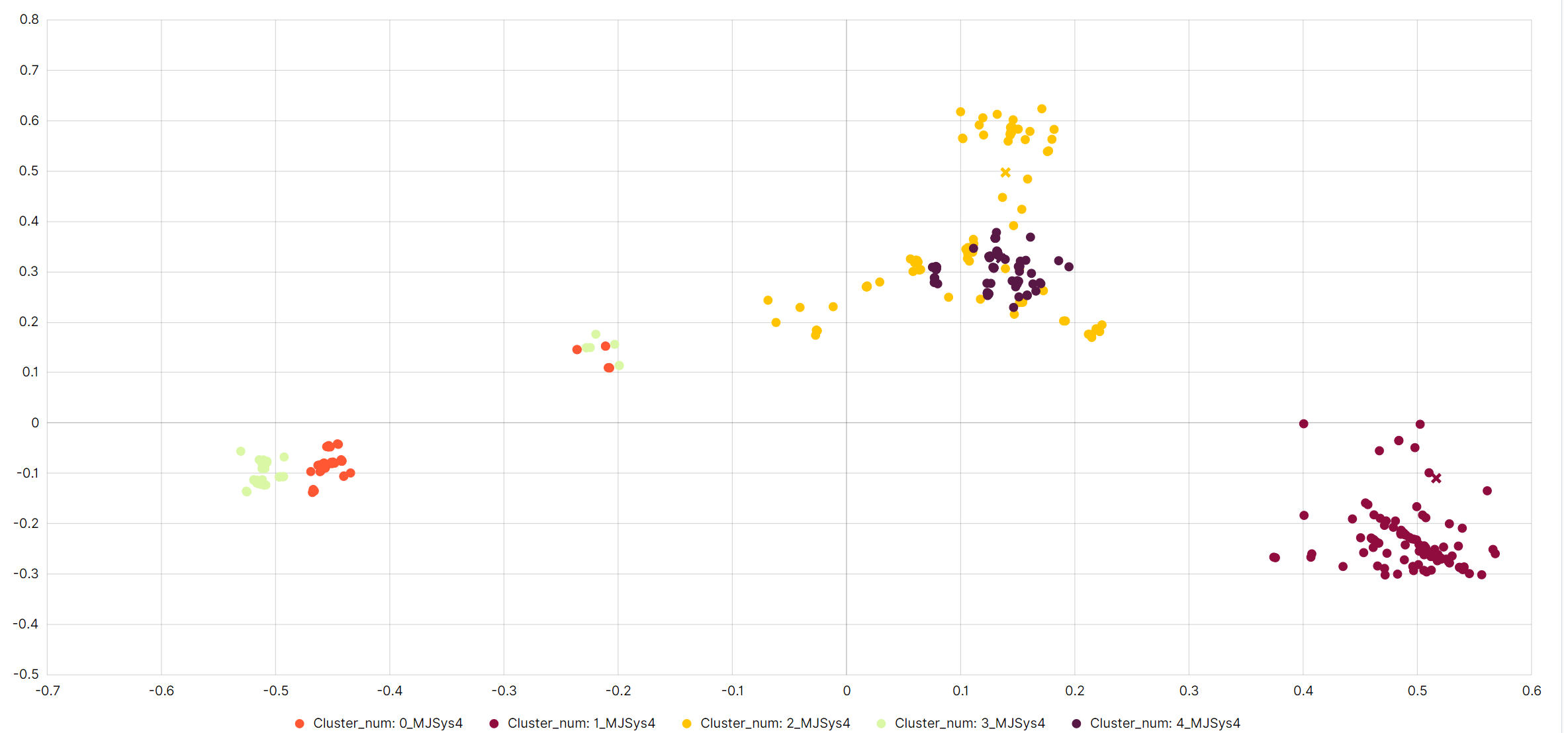
Indicative Number of Documents: The chart shows an indicative number of documents, meaning it does not display the entire dataset. This is done to avoid overcrowding the chart and to provide better readability and data analysis.
Benefits of the Cluster Distribution Chart
The cluster distribution chart helps in:
Visualizing Document Groupings: It enables understanding how documents are grouped into clusters and their distributions.
Quick Anomaly Identification: By analyzing the document distribution, unusual groupings can be quickly identified, which may indicate anomalies.
Analyzing Cluster Centers: Cluster centers help evaluate which features are most representative of a given cluster.
Clustering Result Examples
Below the cluster distribution chart, the Performance tab displays example documents from each cluster. These documents correspond to the dots on the chart and are not a full set but a representative sample.
Understanding the Clustering Result Examples
Document Representation: Each cluster section shows a list of example documents that belong to that cluster. The documents are represented by their content, such as log messages or text data.

Sample Data: The documents shown are not exhaustive. Only a sample is displayed to give an idea of the type of data grouped into each cluster. This helps in understanding the nature and characteristics of the clusters without overwhelming the user with too much data.
Benefits of Viewing Clustering Result Examples
The clustering result examples help in:
Validating Cluster Quality: By looking at the example documents, you can quickly assess whether the clustering algorithm has grouped the documents meaningfully.
Identifying Patterns: Seeing sample documents from each cluster allows you to identify common patterns or features within each cluster.
Quick Reference: The representative samples provide a quick reference to the kinds of documents in each cluster, aiding in faster analysis and decision-making.